
Cart (0 Items)
Your cart is currently empty.
View ProductsIt looks like you are visiting from outside the EU. Switch to the US version to see local pricing in USD and local shipping.
Switch to US ($) Peptide synthesis
Peptide synthesis
 Thomas Meyer
Thomas Meyer
The versatility of peptides has propelled the inclusion of these molecules in multiple applications:

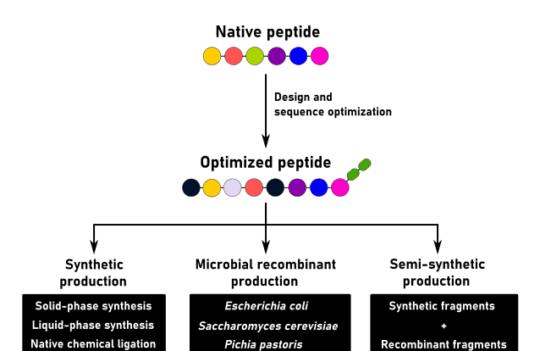
Chemical synthesis is usually the preferred route for peptide synthesis. These methods also allow the careful optimization of peptide’s solubility and stability.
Several principles can be taken into account to optimize the properties of a peptide:
Traditionally, peptides originate from native protein sequences. These sequences can be chemically modified or conjugated with other molecules to increase stability. But they can also be modified by random or site-specific modifications in the attempt to increase the specificity of a peptide towards its intended target.
More recently, peptide research is increasingly evolving to expand the functionality of these conventional peptides by developing de novo peptide design approaches. These approaches, often based on deep learning algorithms, promise to revolutionize synthetic biology by granting new peptides unique reactivities and novel functionalities.
The stability of a peptide can easily be predicted during the peptide design stage. However, its bioactivity is harder to estimate.
In silico prediction software has become an increasingly popular way to predict the bioactivity of synthetic and natural peptides.
However, in the absence of structural information of the target molecule, bioactivity may be impossible to predict using in silico methods alone.
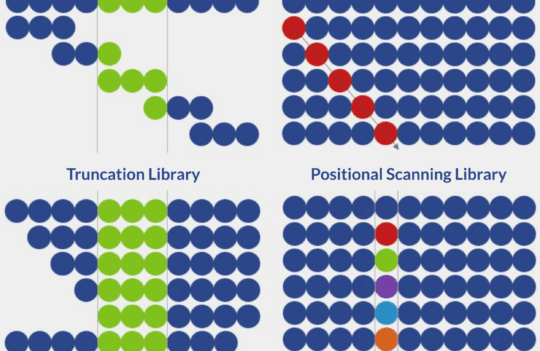
In this way, it is often desirable to use these methods to guide the determination of potential bioactive proteins for the design of peptide libraries. But instead of using them to find the ideal candidate, they can be used to design a peptide library with the most suitable candidates. These libraries, comprising a systematic combination of a large number of different peptides, are compatible with high throughput screening techniques and, therefore, can accelerate peptide discovery.
Peptide libraries can be synthetically generated or created by phage display. However, the synthetic format offers many advantages including ease of library creation and possibility to include unnatural modifications and residues into the peptide backbone.
Peptide design and discovery is increasingly being used to expand the functionalities of natural peptides for multiple applications. These strategies should take into account both peptide stability and bioactivity to obtain the best possible candidates.
However, even the most effective in silico design strategies should include an experimental validation step. For this reason, rational peptide design and library screening should go hand-in-hand to maximize the stability and bioactivity of every new biomolecule.
Join our email list to receive exclusive content featuring the most interesting industry and research news, biologics development tips pieced together by experts, res, company news, and exclusive limited-offers. Join a community of 80,000 subscribers and save up to 30% on your first order.